
When Feature Flags Go Bad
Feature flags, also known as feature toggles, are a powerful tool for developers. They allow developers to turn features on or off within an application after the application has been deployed to production. With feature flags, developers deploy their code once while retaining the ability to toggle certain features when the application runs. There are advantages of feature flags, and carefully using them can lead to:
- Faster deployment: Push out new code without having to wait for a full release.
- Reduced risk: Test new features with a smaller group of users before rolling them out to everyone, and rollback quickly if needed.
- A/B Testing: Test different versions of a feature with different groups of users.
However, like any tool, feature flags need proper implementation and monitoring or things can go bad very quickly.
The Dark Side of Feature Flags
One well-known disaster caused by a careless feature flag implementation is concisely captured in Andy Davie’s talk. It’s a sad story of an American global financial services company that didn’t think through their feature flag implementation.
What went wrong
The company’s development team built a new feature to make the company more money. To control this new feature, they repurposed a feature flag that they created for a different trading algorithm. That old trading algorithm/code was never intended to be used in the real world to process transactions. When the engineer deployed the new code to its eight servers, they made a mistake and did not copy the new code to one of the servers. Instead of doing nothing, the server activated the old code by the repurposed flag.
The simple human error was actually a series of bad practices:
- Reusing a feature toggle.
- Keeping dead code for years
- Manual deployment
- Human monitoring
The result: Knight Capital lost half a billion dollars in just 45 minutes.
Lessons Learned
Knight Capital could have prevented the failure and minimized the damage by following these best practices.
- Never re-use a feature toggle: Re-using a flag is the source of Knight Capital’s feature flag horror story.
- Clean up old toggles: Removing flags once they are no longer needed keeps your workflow clean and organized.
- Automate tests as part of the CI process: Testing feature flags consistently through a continuous integration system eliminates human error.
- Monitor the effects of toggling feature flags: Monitoring and alerting on the state of toggles helps to detect potential problems.
Continue Toggling, Monitor Proactively
The key takeaway from the case study is that feature flags are powerful techniques for faster and safer software delivery in DevOps, but we need to use them strategically and change the way we troubleshoot and “rollback” deployment. Prior to feature toggles, a deployment rollback would roll back the underlying code and remove other features or bug fixes that developers released. With feature toggles, new features that run into issues in production can be “rolled back” without impacting other changes or firing off the old defective code in Knight Capital’s case.
Make Toggles Auditable
Auditing feature toggle state changes is important. Changes to a feature toggle state should report the time and the user that made the change. This information can play a key part of incident diagnosis and post-incident root cause analysis as improper change management is still a leading cause of incidents. Popular feature flag management platforms like LaunchDarkly provide the audit log that gives teams full visibility into their feature flag management—the who, what, and when of all feature flag changes. The audit log contains a record of all the changes made to each feature flag in the system.
CtrlStack integrates with LaunchDarkly to allow DevOps team to monitor feature deployments so you’re aware when issues arise and see clearly any negative impact reflected in the performance metrics. Performing a metric investigation related to any feature flag change takes just 15 seconds.
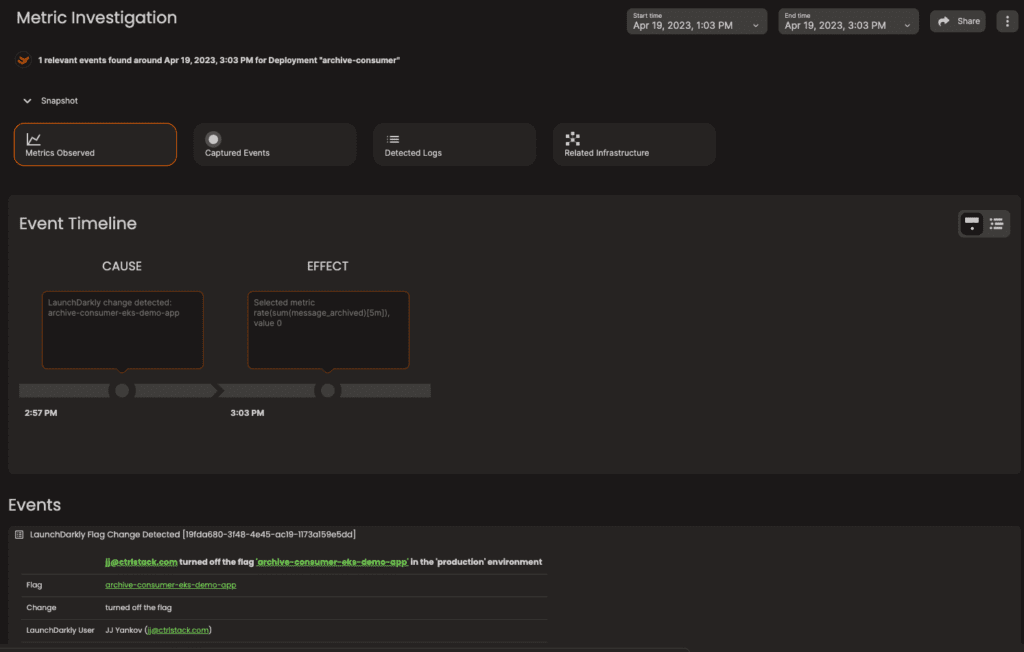
Centralize Events on a Unified Timeline
Improper change management is a leading cause of incidents. Here’s a familiar situation: Before you release a new feature, you test it with QA; If the tests produce good results, you push the new code into production. Unfortunately, the new code is not synced with the infrastructure changes.
By following a timeline of events across your CI/CI pipelines and Kubernete on AWS infrastructure within CtrlStack, you can proactively monitor changes and validate whether or not your infrastructure changes (if any) are valid whenever someone creates a pull request.
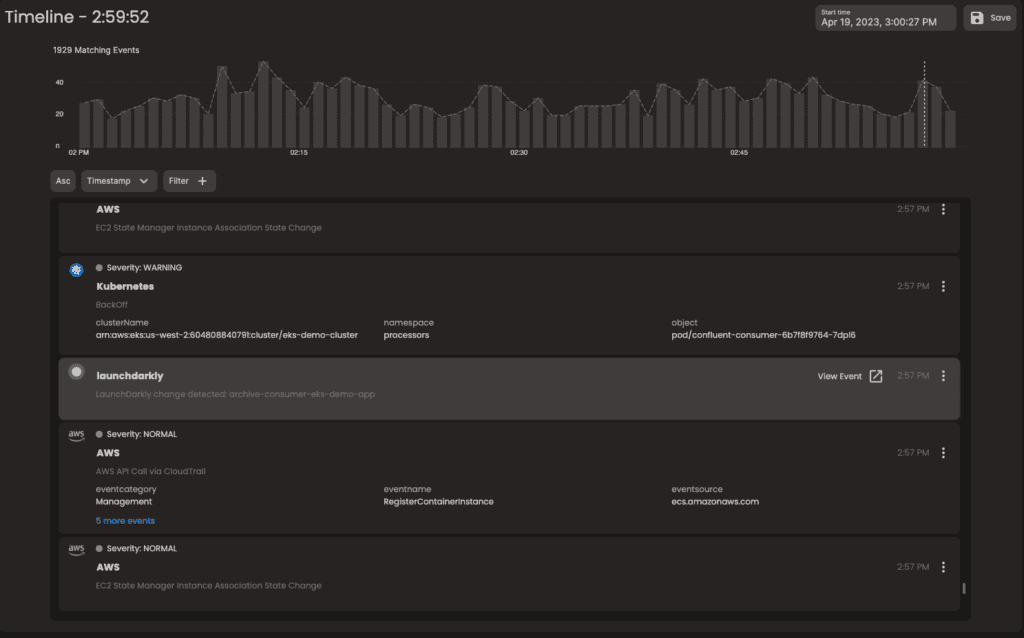
Gain Control, Minimize risk
Feature flags are an integral part of modern product development, but they need to be monitored and used mindfully. It’s common to release several releases per week or even days. The usual practice for Ops guys during the release process is to monitor the deployment, and roll back the version if they find any anomalies. But what happens if someone changes a feature flag’s value in production? Wouldn’t it be nice to notify your teammates when a feature flag is switched on or off?
With CtrlStack, you can centralize events and put them in context for faster incident investigation. With feature flags allowing you to test new features in production, it’s critical that you get visibility of all changes and how they impact other parts of the application or infrastructure. By enriching your feature flag events with infrastructure events, you can be confident that your feature will be successfully launched without unintentionally causing a performance degradation or outage.
If you’re interested in learning more about CtrlStack and how we can help you eliminate blindspots, schedule a call with our expert today.





