Blog
Explore research, insights, and innovation.
-
 BlogJune 21, 2023Two CtrlStack Integrations For Faster Incident Response
BlogJune 21, 2023Two CtrlStack Integrations For Faster Incident Response -
BlogMay 05, 2023GitOps Tools That Enable Automation and Observability
-
BlogApril 20, 2023When Feature Flags Go Bad
-
BlogApril 07, 2023Managing Kubernetes on AWS the Easy Way
-
BlogMarch 28, 2023Change Failure Rate: How DevOps Teams can Improve CFR
-
BlogMarch 13, 2023Why Incident Management Needs Modernization
-
BlogFebruary 24, 2023Kubernetes Troubleshooting: The Right Data and Tools to Use
-
BlogFebruary 08, 2023Connect Kubernetes Events and Metrics
-
BlogJanuary 27, 2023Site Reliability Engineer: Accelerate the Diagnostic Stage of MTTR using CtrlStack’s RCA Dashboard
-
BlogJanuary 13, 2023Techstrong Group and CtrlStack: Minimizing the Troubleshooting Tax
-
BlogJanuary 02, 20235 Ways That Generative AI Will Transform DevOps in 2023
-
BlogDecember 15, 2022Introducing CtrlStack: Connecting Cause and Effect for Cloud Apps
-
BlogDecember 05, 2022Incident Management Challenges CtrlStack Solves
-
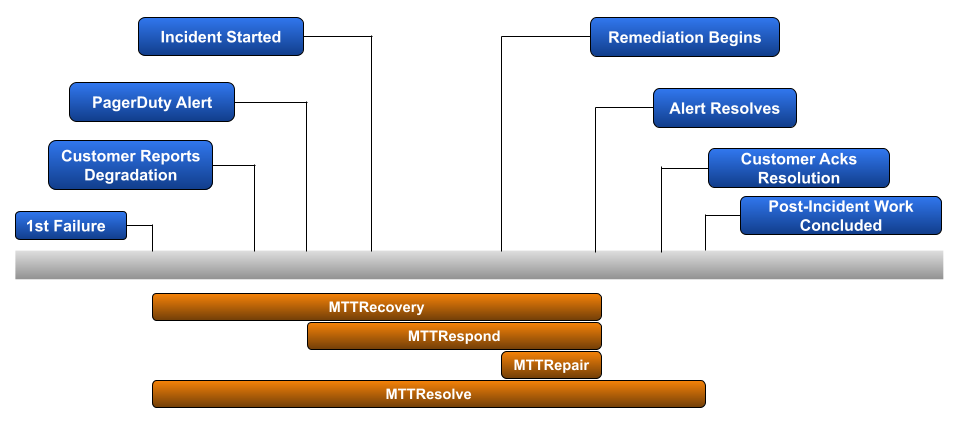
BlogNovember 21, 2022Branching Out from MTTR: Tracking MTTD, MTBF, and MTTA
-
BlogNovember 17, 2022The Impact of Hidden Changes in DevOps
-
BlogOctober 26, 2022Traceability in Observability — Not What You’d Think
-
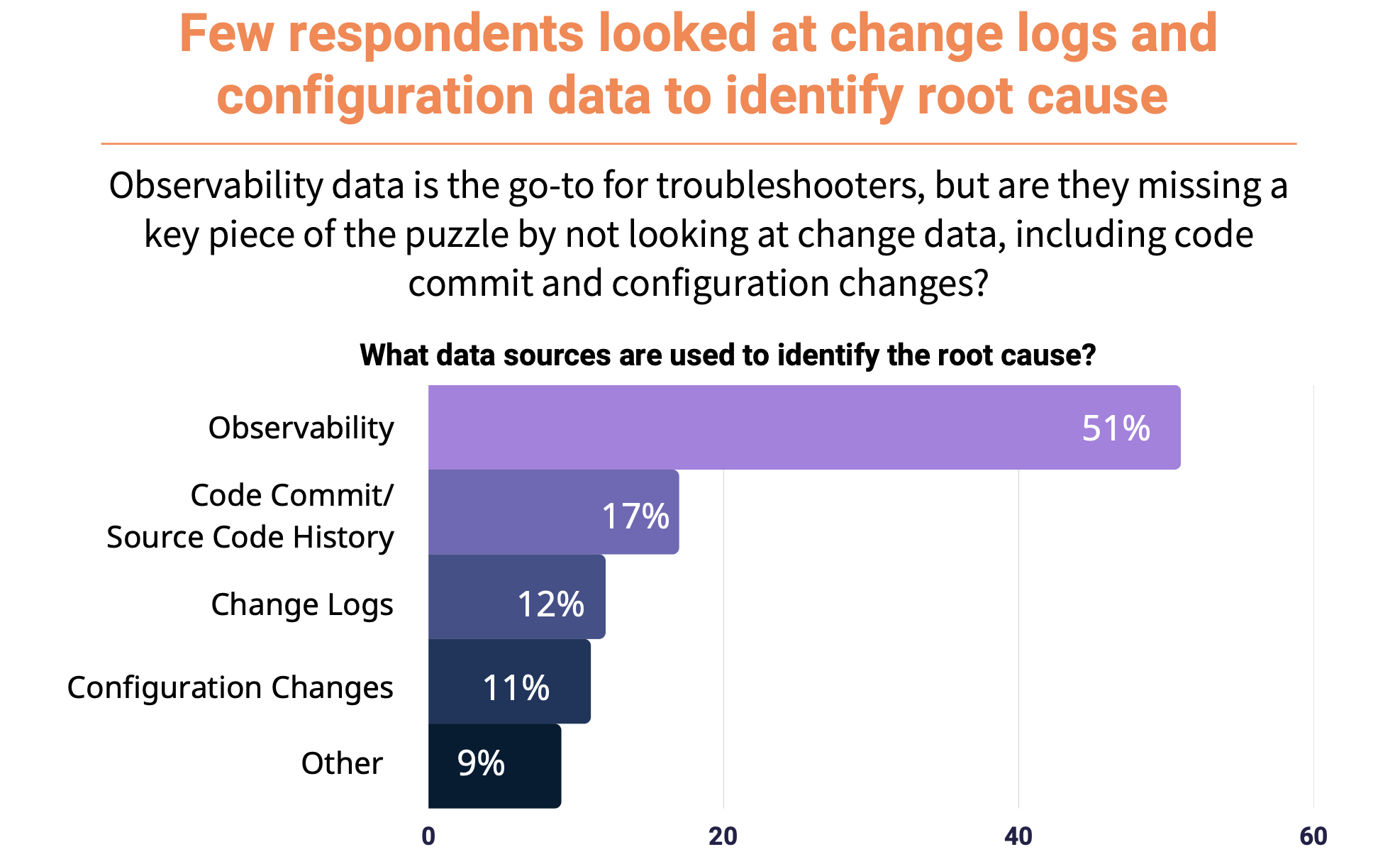
BlogOctober 12, 2022What Changes Do Most Observability Tools Miss?
-
BlogOctober 06, 2022Getting To The Root Of MTTR
-
BlogSeptember 29, 2022AWS Flawed: Silent But Deadly; why AWS Errors Stink
-
BlogSeptember 22, 2022Root Cause Analysis: How can an idea that’s wrong be so useful?
-
BlogSeptember 07, 2022When DevOps Dominoes Come Crashing Down
-
BlogAugust 31, 2022Why Siloed Monitoring Hit the Wall