
5 Ways That Generative AI Will Transform DevOps in 2023
If there’s been a dominant technology theme in 2022, it’s Generative AI. From mainstream image generation (Dall-E, MidJourney, Stable Diffusion, Lensa) to broad conversational AI (ChatGPT) to code generation (Copilot), we’ve seen a series of breakthroughs in large language models (LLMs) that seem to have no clear limit. (Spoiler alert: they do, and we’ll get to those!)
Larger transformer architectures, reinforcement learning through human feedback (RLHF), improved embeddings, and latent diffusion have brought seemingly magic capabilities to an unexpectedly broad set of use cases. How will these breakthroughs affect our little corner of application management and DevOps? I give you five predictions for 2023:
- Infra-as-Code becomes DevOps-As-Code
- ChatOps is Dead. Long Live ChatOps (v2)
- Search Mind-Melds with Generation
- Scaling Generative Troubleshooting
- Generating (Chaotic Good) DevOps Supervillains
1. Infra-as-Code becomes DevOps-As-Code
When Infra-as-Code came along, the benefits were obvious from the beginning – less manual work, better tracking of changes, replicability/consistency, less configuration drift, easier deltas/updates, safer scale-out. However, Infra-as-Code is really about provisioning systems/services, and the world of application management/operations has many other processes that aren’t automated and don’t enjoy those benefits – service configuration, troubleshooting and root cause analysis, incident remediation, performance management, complex code deployment, cost management/optimization, and auditing/compliance, just to name a few.
Automating these tasks is difficult for a variety of reasons. They involve multiple systems and interfaces. They tie together real-time data with actions in a way that can’t be expressed in declarative manifests. They require deeper data and models than we collect, at the moment. They may have complex branching logic that doesn’t fit into linear workflows. And legacy automation tools often use clunky flowchart interfaces that are fragile and visually unscalable.
The way forward is through code. At scale, it takes code to run code. Code can express the logic we need, can tie data to actions intuitively, and can scale to enormously complex algorithms with modularity and encapsulation. But because code is difficult to write and maintain, its role in ops automation has mostly been limited to the most frequent workflows, not the larger universe of daily tasks like those above.
Code generation will radically lower the threshold for which DevOps flows can be automated effectively and efficiently. Starting from low-level tasks and building a hierarchy of automation upwards, code generation tools will be able to capture and distribute operational process knowledge across teams and across companies. Robotic process automation (RPA) will capture activity as code, while Generative AI can help encode flows that have never been seen in the wild.
One key question is what that code looks like, and in particular, which language and run-time. Our bet is on Python as it’s 1.) the most popular language in the world, 2.) the standard for machine learning frameworks in particular, and also 3.) one of the most mature targets for code generation tools (e.g., it was the first language targeted by Github Copilot).
CtrlStack already uses generative AI to turn natural language application queries into Python code which renders the view…but we’re just getting started.
2. ChatOps is Dead. Long Live ChatOps (v2)
You probably remember when “ChatOps” got hot in 2016-2017 and then slowly faded.
Google Trends remembers.
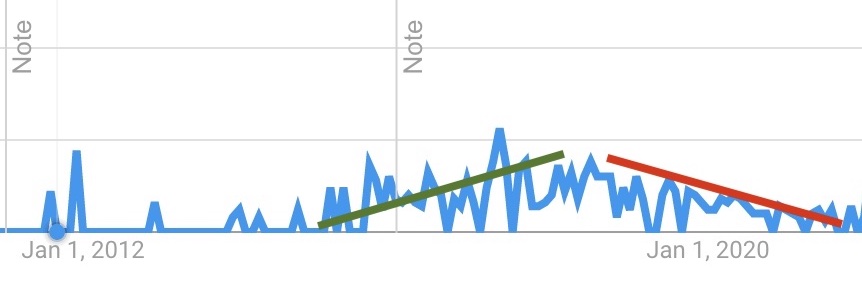
The early arguments for ChatOps made a ton of sense – we spend most of our day in team chat. Our brains evolved over millennia for social modeling and interaction. Conversational interfaces could mediate not just humans and systems but even humans and other humans, scaling up coordination beyond our current abilities.
But ChatOps v1 wasn’t really conversational – not really. We didn’t have the models to take natural language as input or provide user-customized language output. Instead, ChatOps v1 really looked more like a terminal command line within Slack or Teams, with rigid syntax and thus a lot of cognitive overhead and context-switching.
ChatOps v2 will be powered by modern LLMs and be able to accept much more human input. Beyond that, it will be able to leverage the existing conversations within channels to build context, and suggest the right data/actions at the right time. It will be able to route a wide variety of different use cases to the right data set, API, person, or team. And it will be able to bring different people and teams up to speed in customized ways that will transform coordination. We’ll see this in 2023.
3. Search Mind-Melds with Generation
Search engines are really good at connecting you to existing resources based on intent. That’s been the same since the early days of the web 30 years ago (Excite, anyone? Lycos? Altavista? Good lord, I’m getting old.)
However, if you take a step back, you realize that most search engine traffic isn’t trying to get to a specific destination (navigational/transactional), but is informational – like 80% of all traffic. For navigational/transactional queries, the search engine paradigm makes sense: intent => URL. But for informational queries, the right information presented in the right way might not actually exist anywhere in the world, as a URL – instead, it might need to be generated on the fly. This is the opportunity for LLMs in search, or Generative Search.
ChatGPT excels at this kind of declarative knowledge and at molding that knowledge for a broad set of audiences. Here, we’ll ask about nuclear fusion for a 5-year old, an 18-year old…..and a Star Wars fan.

Extra credit for the bouncy “Sure!”. Five-year olds need a little warning buffer to pay attention.
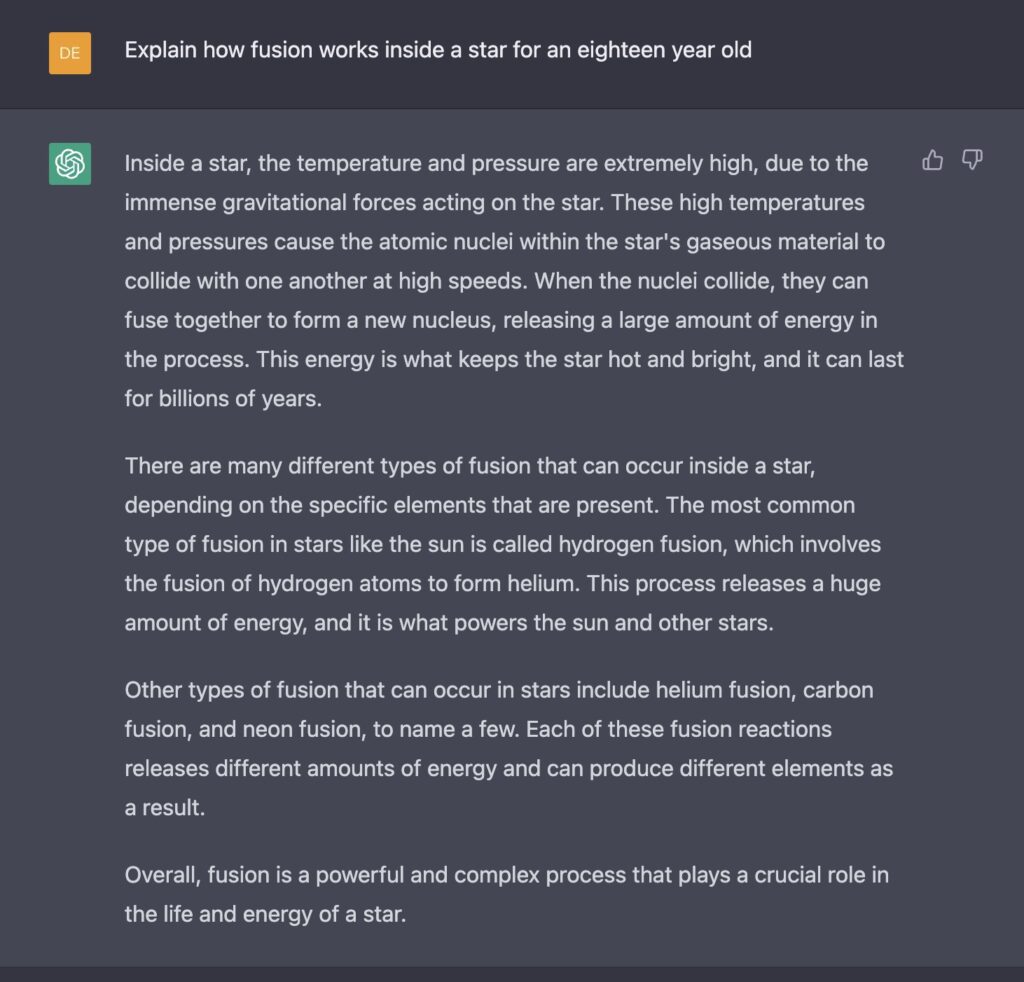
Very credible as an introduction in a high school physics class.
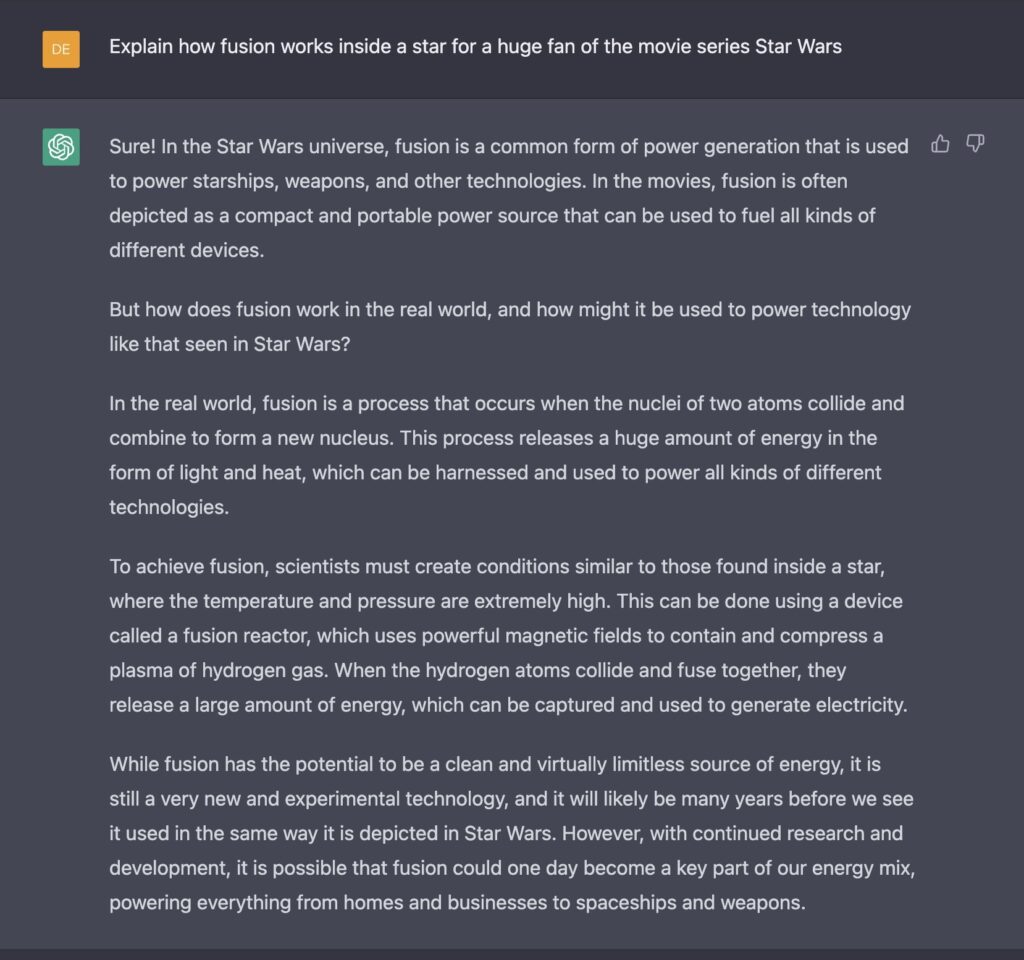
Not bad! Start with the specific interest as background context, pivot to the real world, throw in some more fan service at the end – at least a 9/10, and available in mere seconds. This answer didn’t exist until it was searched for.
Our recent release of PromptOps shows the power of this approach for DevOps — you can type a natural language question about a Kubernetes query/action and get back a specific, custom kubectl command with references, even specific command lines that don’t exist anywhere on the web. PromptOps uses the conversational context so that you don’t need to specify the exact entity name each time.

4. Scaling Generative Troubleshooting
Cloud application troubleshooting is broken. The median downtime (MTTR) is more than 5 hours, according to a 2022 study by Splunk. 76% of all performance problems are traceable to changes made to the environment, and 66% of MTTR is spent trying to figure out which change caused the problem. To put it bluntly, these are not the signs of a solved problem.
The reasons behind these symptoms go a bit deeper — part of it is a data issue, that we don’t track changes we’re making to the system, or build a model that connects cause to effect, or rationalize our observability data across data types/formats. But a lot of it is process knowledge — really, tribal knowledge: queries might be sub-second fast, but knowing what to query is slow and often requires battle scars.
With the right data context, Generative AI can help extract signal from the noise and automate large parts of the initial troubleshooting flows. Beyond encoding our manual troubleshooting process (through robotic process automation), generative approaches will be able to navigate unusual data to determine whether 1.) there’s actually a real problem and 2.) what the most-likely causes were. We call this smoke-fire-match; first, does the smoke (a metric alert or anomaly) represent a real fire (problem)? And then, what match (root cause) started that fire, and when/where?
Generative approaches will also streamline the remediation confirmation and coordination steps, closing the loop on incident management.
5. Generating (Chaotic Good) DevOps Supervillains
Chaos engineering first gained attention within Netflix a decade ago with their Chaos Monkey tool, which was eventually open-sourced. Chaos Monkey would attack different parts of the Netflix application (on purpose), forcing the ops team to respond in real-time and test out remediation, both manual and automated. Open source tools like Litmus, ChaosBlade, and Chaos Mesh have extended this approach to other parts of the stack.
However, these approaches have two huge drawbacks — the classes of attacks are relatively generic/fixed, and the remediation is a slow and manual process. If you frame chaos engineering as an improvement loop, these drawbacks made the overall process slow and fragile.
Generative approaches promise to radically expand the quantity and quality of meaningful situations, and help automate the remediation side in response. (Indeed, I actually worked on a reinforcement-learning-driven version of this loop from 2017-2020). The power of modern transformers means that larger action spaces and more complicated systems are within reach for the attacking side, at the same time that faster and more capable automation is possible on the remediation side — massively accelerating the overall learning loop and providing new levels of robustness. We’ll see the first hints of this in 2023.
The Outer Limits
As we alluded to earlier, modern LLMs still have a number of limits. Other authors have gone into depth on these, but I’ll just lay out three tensions with some specific examples from ChatGPT (not to pick on ChatGPT as the most problematic LLM, but as the most mainstream/accessible one). All of the examples below were executed after 12/28/22.
Correlation vs. Causation
Current LLMs like ChatGPT can’t really reason about causality; at their core, they’re essentially looking at sequences of tokens that are correlated. Here’s a simple example of a question which will elicit an incorrect answer about causality:

Now, a 5-year old (or a Bayesian network, to be fair) might say this, but a 10-year old wouldn’t. Still some work to do here.
Syntax vs. Semantics
The symbol grounding problem is a little beyond the scope of this essay, but think about the relationship between the phrase “my phone” (the formal symbol) and the actual phone that we can hold, see, and hear in the real world (the referent). For us, language isn’t just a formal game, but a portable representation of something else.
LLMs don’t have access to the actual phone or the world at all – they’re purely in the business of manipulating formal symbols, looking for patterns and relationships. They’re in Plato’s Cave, trying to tell stories about shadows on the wall. And if a specific pattern didn’t show up in the shadows, they can’t dig deeper to fix the issue:
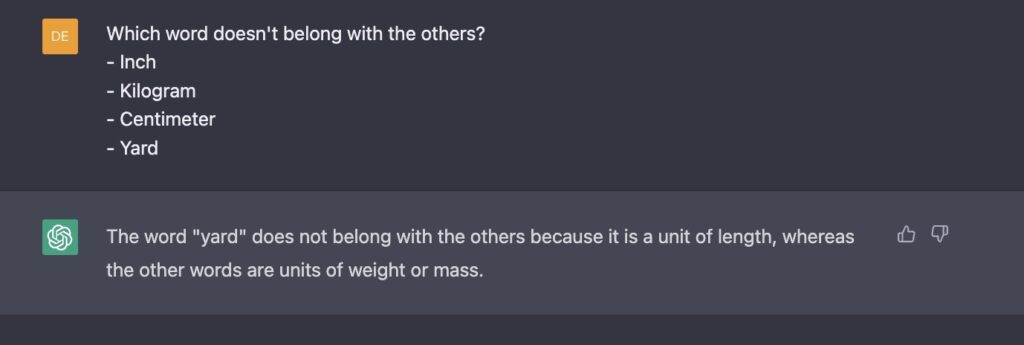
Whoops!
Embodied vs. Disembodied
ChatGPT was trained on a fixed corpus of text, and as a result, doesn’t have any knowledge past 2021. ChatGPT also can’t access external resources (like the web) in real-time – it’s a frozen time capsule of data from over a year ago. Cognitive psychologists talk about the “4 E’s of Cognition”; that cognition isn’t an isolated computational process, but is embodied, embedded, enacted, and extended in and by the environment. ChatGPT isn’t any of these.

To be fair, ChatGPT tries to protect against other current event queries for things like stock prices and sports, so at least you don’t anchor on incorrect information in those cases. But outside of those cases, ChatGPT doesn’t know what it doesn’t know.
The Future of LLMs
However, these three tensions aren’t hard information-theoretic limits on AI. In fact, there’s active research into reconciling all three of these tensions with the incredible power of LLMs. As they do, they’ll unlock even more use cases – for DevOps and for other fields. Stay tuned.





